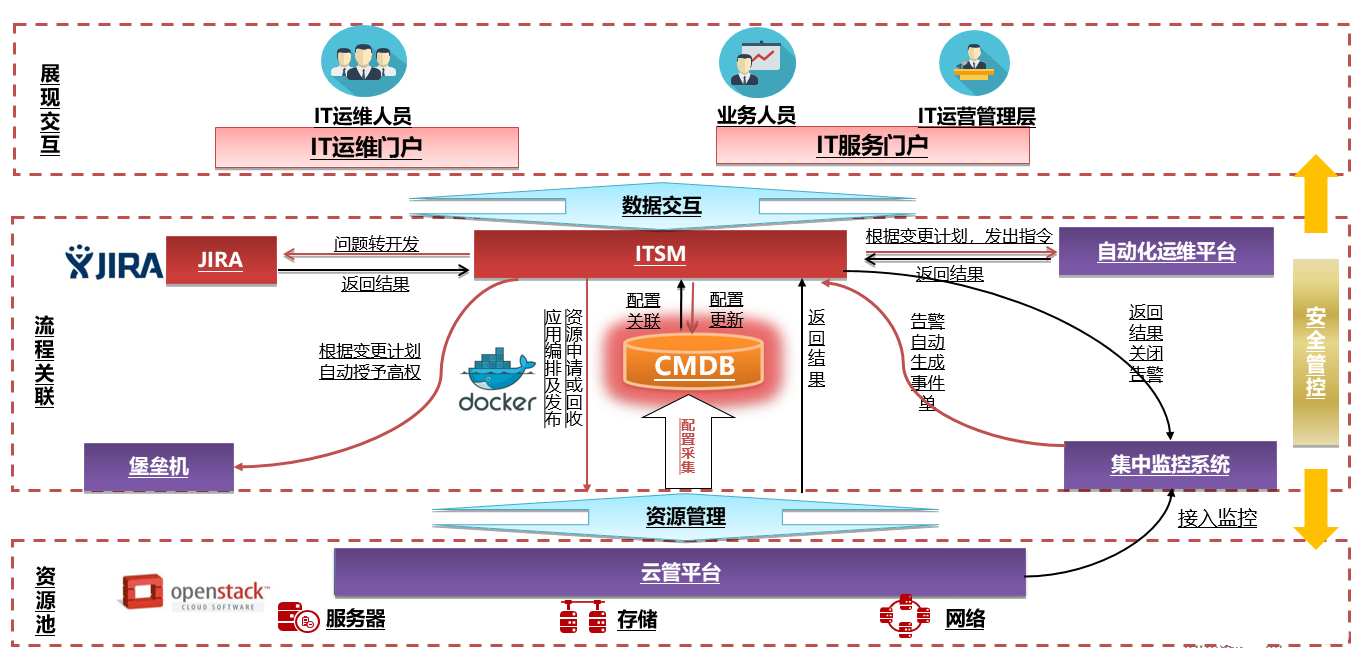
IT運維管理(IT Operations Management)就像是企業的IT系統管家,負責讓整個技術架構平穩運行。想象一下,一個公司有上百臺服務器、網絡設備、各種軟件系統,這些都需要7×24小時穩定工作。IT運維團隊就是確保這些"數字基礎設施"不宕機、不出錯的幕后英雄。ServiceHot作為ITSM 2.0倡導者,將傳統運維升級為更智能的運營模式,通過自動化工具實時監控系統健康狀態,就像給IT系統裝上了"智能體檢儀"。現代運維早已不是簡單的修電腦、重啟服務器,而是包含配置管理、容量規劃、變更控制等專業領域。比如當系統流量突然激增時,運維平能自動擴容云服務器;當發現安全漏洞時,可以一鍵下發補丁。ServiceHot ITSOM平臺正是把這些復雜場景變成可視化、可量化的管理流程,讓運維從"救火隊"轉型為"預防專家"。
it運維管理年終工作總結
又到一年盤點時,IT運維人的年終總結往往寫滿驚心動魄的故事。今年我們通過ServiceHot運維平臺處理了3287個告警事件,平均響應時間從去年的47分鐘縮短到12分鐘。最驚險的是雙十一期間,電商平臺每秒訂單量突破5萬筆,但基于ServiceHot的智能容量預測功能,我們提前兩周就完成了服務器集群擴容。在成本控制方面,通過資源利用率分析關停了137臺閑置虛擬機,節省了28%的云計算開支。值得驕傲的是,今年首次實現全年核心系統零重大故障,這要歸功于ServiceHot的故障自愈功能——有次數據庫主節點宕機,系統在90秒內就自動完成了切換。當然也有教訓,某次變更忘記在測試環境驗證,直接導致生產環境服務中斷15分鐘。現在我們都養成了用ServiceHot變更管理模塊走標準化流程的習慣。展望明年,計劃將AIOps功能深度應用到日志分析中,讓機器幫我們發現更多潛在風險。
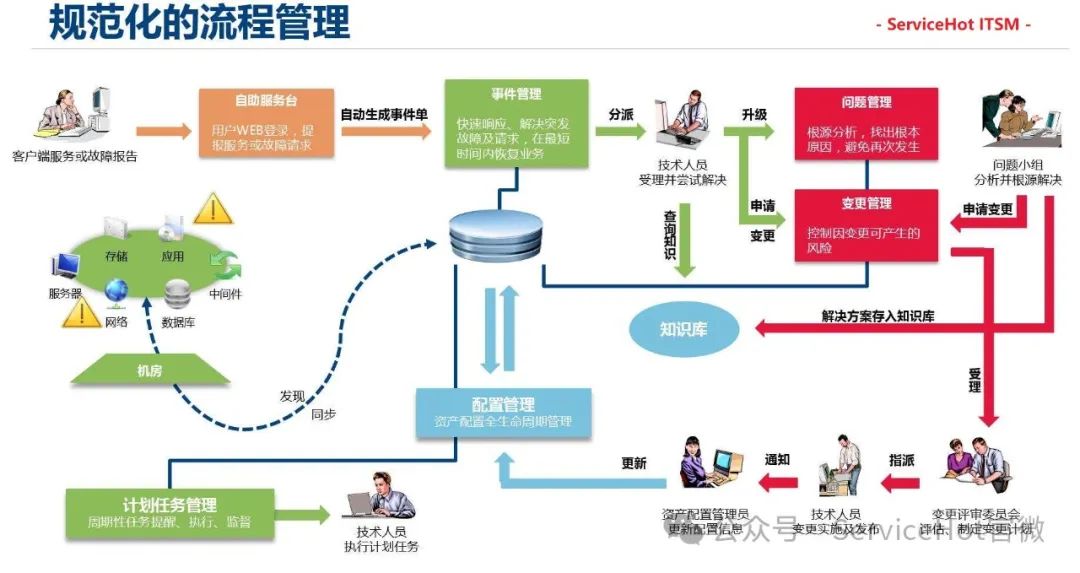
淺談事件管理
事件管理是IT運維的"急診科",處理不好隨時可能演變成業務災難。在金融行業有個經典案例:某證券交易系統突然出現延時,傳統監控只能看到服務器CPU飆高,但通過ServiceHot的事件關聯分析,發現是某個微服務調用Redis時產生了死鎖。這就是現代事件管理的精髓——不僅要看到現象,更要定位根因。我們常把事件分為"尖叫事件"(比如官網崩潰)和"沉默事件"(緩慢的內存泄漏),后者往往更危險。ServiceHot平臺的事件風暴抑制功能特別實用,上周有個網絡抖動原本會觸發2000多條告警,系統自動歸并成3個有效事件單。還有個反常識的發現:60%的嚴重事件其實由小變更引發,所以我們現在嚴格執行"變更-監控-回滾"的閉環管理。最近正在試驗用ServiceHot的預測性維護功能,通過對歷史事件的學習,系統已經能提前4小時預測到磁盤寫滿風險,這讓運維真正有了"預見未來"的能力。